Value in Aggregate Clay Shirky's latest newsletter, on Grid Supercomputing: The Next Push, devalues computation relative to communication and questions the value proposition of grid computing. He makes some great point, but I think he is right about relative value, albeit the irony that grid computing is enabled by communication.
When I think of grids, I think of bell curves. MIPS, Mbs & Mbps have become fungible datacommodities. Grid computing provides means of aggregation. When aggregated you pool risk.

Your average company utilizes datacommodities in a bell curve that maps to the duration of a day, with a peak utilization a little before noon. This bell curve follows the sun in a daily cycle. A company in California has a different demand curve than one in NY, creating an potential overlap in preferences. Grid computing allows those preferences and risks to be pooled, flattening the curve in aggregate. The key to making it work is the transaction costs of shifting granular supply from one place to another, billing for it and managing its performance. Virtualization technologies in grid computing and data centers are advancing to make these otherwise smart services dumb.
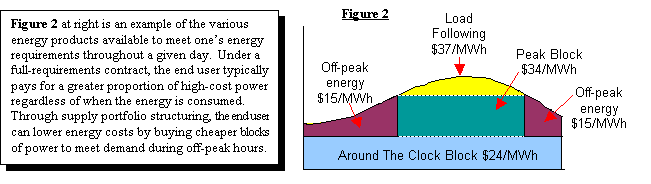
Californians became intimately acquainted with the danger of bursts at the peak, falsified or not, in the electricity market. Here is an example of how pricing is differentiated for load aggregation according to base, peak, off-peak and burst:
Sure processing is relatively inexpensive and has Moore's Law on its side. Grid computing isnt for individuals. When costs are added up for a large organization, hosting farm or major project they are significant. Pooling costs and risks in the aggregate has its benefits.
IBM's marketing whizes have it right in promoting the on-demand potential of grids. Nothing panics decision makers more than the risk of not having enough capacity available at a key unforseen moment. They will pay a premium for capacity on demand or as an insurance policy.
8:04:51 AM  -- Others on this topic: Clay Shirky | Grid Computing -- Others on this topic: Clay Shirky | Grid Computing
|





