|
 |
Tuesday, June 24, 2003 |
- Conflict, Action and Suspense, William Noble
- Characters and Viewpoint, Orson Scott Card
- Scene and Structure, Jack M. Bickham
- Beginnings, Middles & Ends, Nancy Kress
- Voice & Style, Johnny Payne
- Setting, Jack M. Bickham
- Plot, Ansen Dibell
- Description, Monica Wood
- Manuscript Submission, Scott Edelstein
12:43:31 PM 
|
|
|
Monday, April 14, 2003 |
I'm a pack rat. I collect gazillions of bookmarks, articles, copies from books, and PDF files. Today is about clearing out the flotsam of my collection of bookmarks relating to my development environment and tools.
This entry will be a work-in-progress until I've got everything cleaned up and captured here.
Tools & Packages
Mostly to Use in Development
Mostly to Look at for Ideas
Configuration Management
Repository
I have to decide between CVS and Stellation on this one...
Build
Project Information/Metrics
Project Status: Defect Tracking / Enhancement Requests
I have to decide between Scarab and Bugzilla on this one...
Languages
Python
Java
Windowing / GUI
IDE / Interface Builders
Know and Love
Evaluate
Libraries: Java
Know and Love
- TM4J - Topic Maps for Java
- XOM XML Object Model
Evaluate
Libraries: Python
Know and Love
Evaluate
Libraries: C/C++
Know and Love
Evaluate
References & Documentation
8:53:00 PM
|
|
|
Saturday, April 12, 2003 |
Go and post a comment on one of Sam's blog entries. Be sure to misspell a word or two. Coolness!
12:30:18 PM
|
|
|
Sunday, February 09, 2003 |
Here are several papers (some via Lilia via McGee) that inform my thinking about the NewTool platform:
9:08:34 PM
|
|
Knowledge Work as a Process
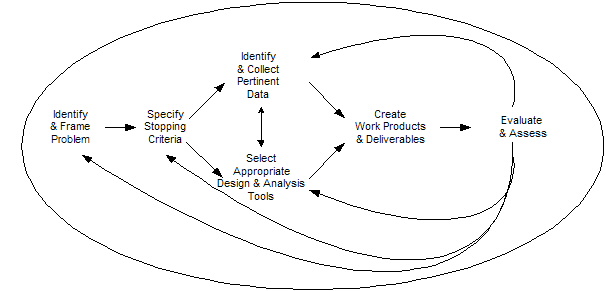
Jim McGee says that the goals of most knowledge management efforts today harken back to Taylorism (scientific management) with onerous command and control ideas and language as opposed to an recognition that knowledge is embodied in humans and any "management" of knowledge must take this fact into account.
NewTool acknowledges the human synthesis of information into knowledge and of knowledge into knowledge and tries only to augment human capabilities to allow focus on the process of synthesis and creation:
This is a process that is fundamentally iterative. The loops in this process are feedback loops, not opportunities for streamlining. You don't improve this process by rearranging the steps or breaking them down into specialized tasks to be distributed. Nor are there opportunities to eliminate non-valued added steps. Improving the value of knowledge work calls for different strategies. Two that are worth exploring are to improve the infrastructure at the periphery and to eliminate friction. [Is knowledge work improvable?, McGee's Musings]
11:32:00 AM
|
|
|
Thursday, February 06, 2003 |
Whiteboard drawing of NewTool - an open source platform for Free Media and Microcontent + (universal) personal proxy/server + authoring and replication
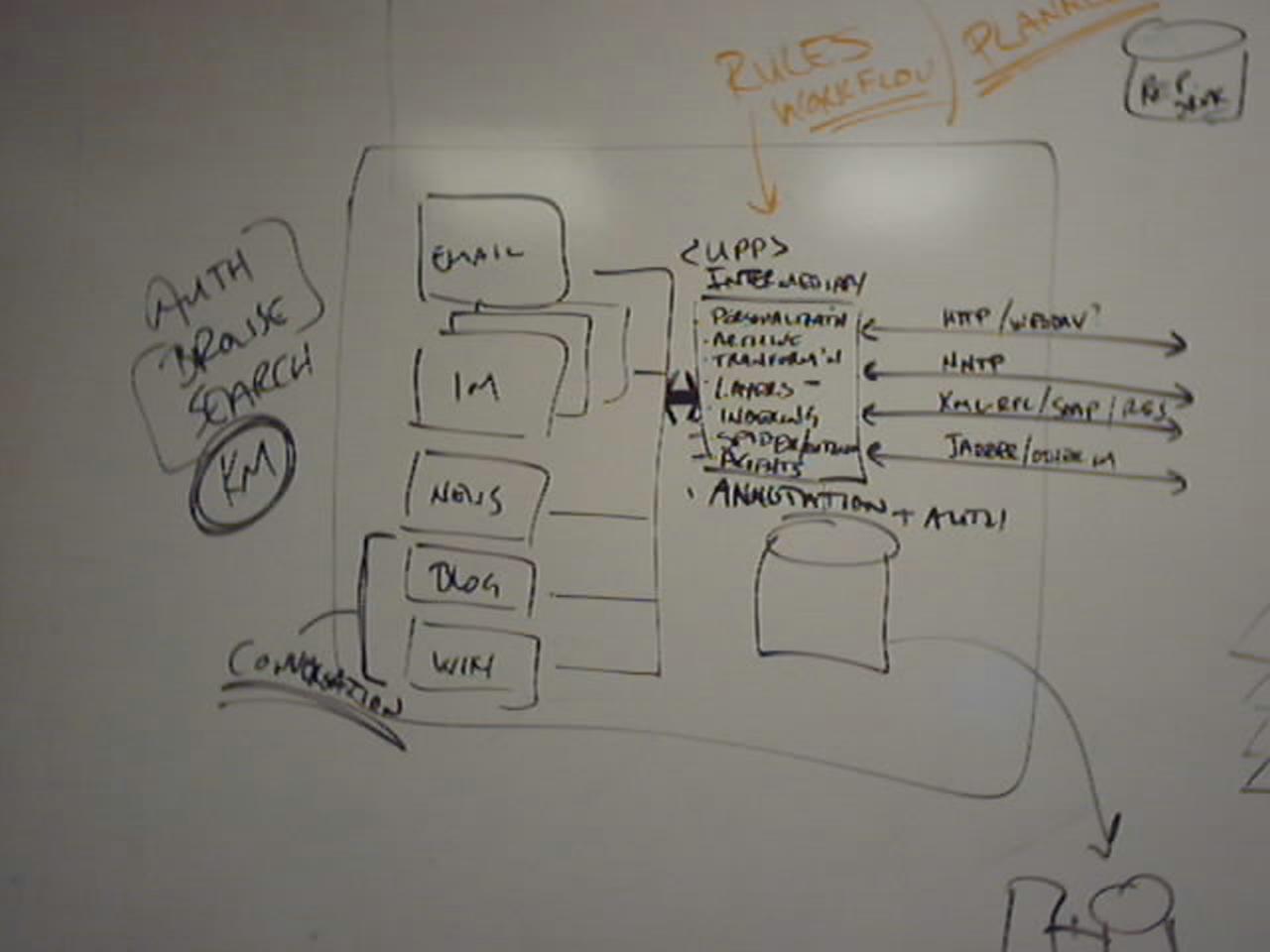
A sampling of references/influences/thought-starters for those interested in talking about this:
3:03:18 PM
|
|
|
Thursday, January 30, 2003 |
Thoughts about Search Engines and Communication. When we do a search on the Internet we are seeking an answer to a question, looking for information. We want to make a query and get an accurate response, free of irrelevant and distracting information. The art of using search engines effectively is the art of framing a question. To frame a question for a search engine we must keep in mind that we are asking a machine for an answer, a machine that does not know the associative meanings that we take for granted when speaking with people. Look at the gif diagram (http://www2.eou.edu/~jhart/netcomdiagram.gif); it represents a simple view of Internet Communication, with just two people and two machines. P to P is person to person communication; M to M is machine to machine communication; P to M is person to machine communication; M to P is machine to person communication. Clearly the ways a machine communicates with another machine will be different than the ways a person communicates with another person. Similarly, a person to machine communication is different from a machine to person communication. The trick in all this to recognize that what works with one relational direction of communication will not necessarily work with another direction. Obviously, if machines communicate with people the way that they communicate with one another, then people will not get the message. If people communicate with machines the way that they communicate with each other, then machines will not get the message. Many of the challenges of the modern age of Internet communication are summarized in the directional lines of this one simple, communications rectangle (except the complexities are multiplied many times over when we add millions of people and millions of machines). As I understand it, the great effort now underway to construct a semantic web is an effort to enable M to M communications to utilize associative meanings; such semantic enhancements could yield emergent communications that are not now available between machines; those semantic communications could then facilitate M to P and P to M communications beyond the levels that are now available. (See http://www.w3.org/2001/sw/;"The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation." -- Tim Berners-Lee, James Hendler, Ora Lassila, The Semantic Web, Scientific American, May 2001.) One of the best ways to reveal the limits of current search engines is to start with the end result, i.e., begin at the end of the search rather the the usual start of the search. Begin with the answer rather than the question. E.g., if you know that you want to find the online instructional resource site MERLOT, you can see how effectively a search engine takes you to your sought-after target. In a typical search you can't know fully in advance where or what your target is, so you can't evaluate how effective or ineffective the search engine is in helping you find what you are looking for. A simple Google search for "MERLOT" works very well, bringing up contacts with the sought-after target in the first five listings before diverging into sites for Merlot wines. However a KartOO search does not succeed as well; it does bring up the desired taste.merlot.org repository address but most of the other listings are for wine sites. If the spelling of the search term is changed from "MERLOT" to "Merlot" something a person unfamiliar with the repository listing might do, then the KartOO search engine is even less successful at identifying what is sought. If a more advanced search technique is applied, using "MERLOT Educational Resources" as the search phrase, then the results are much more targeted, with all wine listings removed. But notice that I had already adjusted my search language to talk to a machine from the first search. If I do a Google search with the kind of query that I'd use with a person ("Find the MERLOT instructional resources site") then Google finds nothing. KartOO does do much better because it has been set up to accept plain language queries ("Find the MERLOT instructional resources site"?), but it does take 7 pages of listings to finally turn up the taste.merlot.org address; instead it brings up many sites that refer to MERLOT. The AskJeeves search engine also provides plain language search capabilities but found very little when give the "Find the MERLOT instructional resources site" instruction and did not locate the desired MERLOT address. Also notice that even in the plain language search example, I kept my language very simple so that I was still doing "computer speak" rather than "people speak." If I were speaking with a librarian or instructional support person I'd use a much more complicate set of instructions such as "Please help me find the MERLOT instructional resources site and all other repositories of online instructional resounces. I want to restrict the search to higher education resources and resources in English. I'd like to exclude all discipline-specific sites." Just for fun I tried this complete set of instructions on Google and did get a number of relevant sites, even though Google indicated that it "limits queries to 10 words." When I tried the same complex set of instructions on KartOO nothing was located. It's impressive to me that the Google algorithms were able to reductively cope with the the complex set of instructions and yield items of use--even though Google was unable to fulfill the complete set of instructions. It's also impressive that the advanced search tools in Google and KartOO and other search engines permit a searcher to construct a complex sequence of searches once the person learns the search protocol language of the software. I'm not sure what to conclude from this brief analysis, except to say that the field of knowledge management and the study of human/machine communication is very much a work in progress. What is encouraging is that the fields exist at all and that progress is underway. However we are a long way from the kinds of conversational communications with machines that are so popularly depicted in science fiction books and movies. [EduResources--Higher Education Resources Online]
9:01:39 PM
|
|
|
Wednesday, January 29, 2003 |
The Digital ID Federation Myth
The key to any federation is understanding who's in it and who's out. The
Digital ID federation concept sounds attractive, but doesn't include the customers,
whose voice and stake in the game are like American Indians in post-Civil War
America. Just because the federation issues get ironed out doesn't mean they'll
do us any good.
But were we to assume that everyone controls their own web space, we have
the foundation of an authentic federation.
Self-hosted Identity
Ming discussed self-hosted
identity on Monday, worth repeating verbatim:
James
Snell talks about being in control of one's own identity and
storing it on one's own site, like as part of one's weblog:
"A discussion on
Sam's blog got me thinking about self-hosted identities. Ideally, I
should be able to put together a file, discoverable through my
weblog, and digitally signed with my private key that contains all
of the personal information that I want to make public. When I go to
any type
of forum (like a weblog) or to a commercial site (like Amazon), if
they want
my information, they would do what Dave suggests and
put a "You know
me" button on their page. When I go to the site, I click on the
button, the site asks me for the location of my identity file. They
download the
file and extract the necessary information."
And he follows up here and here .
We need that, of course. I'm tired of having entered my information on
dozens of different sites over the years, and it
being mostly outdated and forgotten. Much better that it is on my computer.
This is a more sophisticated form of the federated ID solution we
baked into our microeconomy. The first step in letting people control their
ID is to bite the bullet and require everybody to have their own web site.
That seems like a big step, but it's shrinking daily. Blogging is one of the
best reasons to cross the website divide, and identity is pretty close.
Xpertweb users assume their transactions are as public as a public company's.
If you want to do a transaction "off the books" you won't want to
do it using your Xpertweb persona(s). But for most transactions, transparency
solves far more
problems than it raises.
The Xpertweb protocols have no need to expose the buyer's financial information.
Payment is made after the sale, through a trusted third party managed
by the buyer, since the final price is dependent on the buyer's rating of the
transaction. The only data needed to start the transaction is how to get the
product or service into the buyer's
hands. This inversion of the transaction—caveat emptor becomes caveat
vendor—solves most of the difficult problems of identity theft and its
handmaiden, Digital ID.
So Xpertweb's ID need not be as complex as Snell's thorough treatment, but the
approach is perfect. Maybe we can convince Ming or James Snell to help out
on
this
feature
for
our open source microeconomy...
The key to Xpertweb's usefulness will be the ease of using the forms, and
having all the buyer's relevant data filled in automatically is a great start.
Blogging for Dollars
An Xpertweb page is basically a web log that keeps track of your words
and comments of course, but extended with a commercial form of highly structured
trackback. Every time the buyer submits a form, any data saved on the seller's
site is
duplicated
on the buyer's
site, by the buyer's trusted script, in the form of an order confirmation page.
Then, as the transaction progresses, the mirrored data store is enriched, culminating
with each party's grade and comment, which is the point of the whole system.
In the agora, everyone can watch each other shopping. The citizens
are on display like the melons. [Escapable Logic]
11:37:48 AM
|
|
© Copyright 2003 Erick Herring.
|
|
 |
 |
 |
 |
| September 2003 |
| Sun |
Mon |
Tue |
Wed |
Thu |
Fri |
Sat |
| |
1 |
2 |
3 |
4 |
5 |
6 |
| 7 |
8 |
9 |
10 |
11 |
12 |
13 |
| 14 |
15 |
16 |
17 |
18 |
19 |
20 |
| 21 |
22 |
23 |
24 |
25 |
26 |
27 |
| 28 |
29 |
30 |
|
|
|
|
| Jun Oct |
|
 |
 |
 |
 |
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}